为了持续追踪基础模型的前沿进展,把自己从错失焦虑和每天反复浏览各类新闻源的低效工作中解放出来,我尝试开发了一个面向基础模型(大语言模型及多模态模型)资讯追踪的智能网站系统。平台以智能摄取代理为核心,通过自动化工作流持续完成信息采集、交叉验证、结构化入库与前端展示,实时追踪基础模型领域最前沿进展,尽可能降低人工检索成本,同时提升信息时效性与准确性。系统在架构上将三类能力分层解耦:
- 摄取智能层:负责多源抓取、字段补全、能力评测与变更生成;
- 数据管理层:负责工作空间版本化、人工审核闸门与关系库同步;
- 用户呈现层:负责高响应展示与统一访问入口。
一、工作流编排驱动的智能摄取引擎
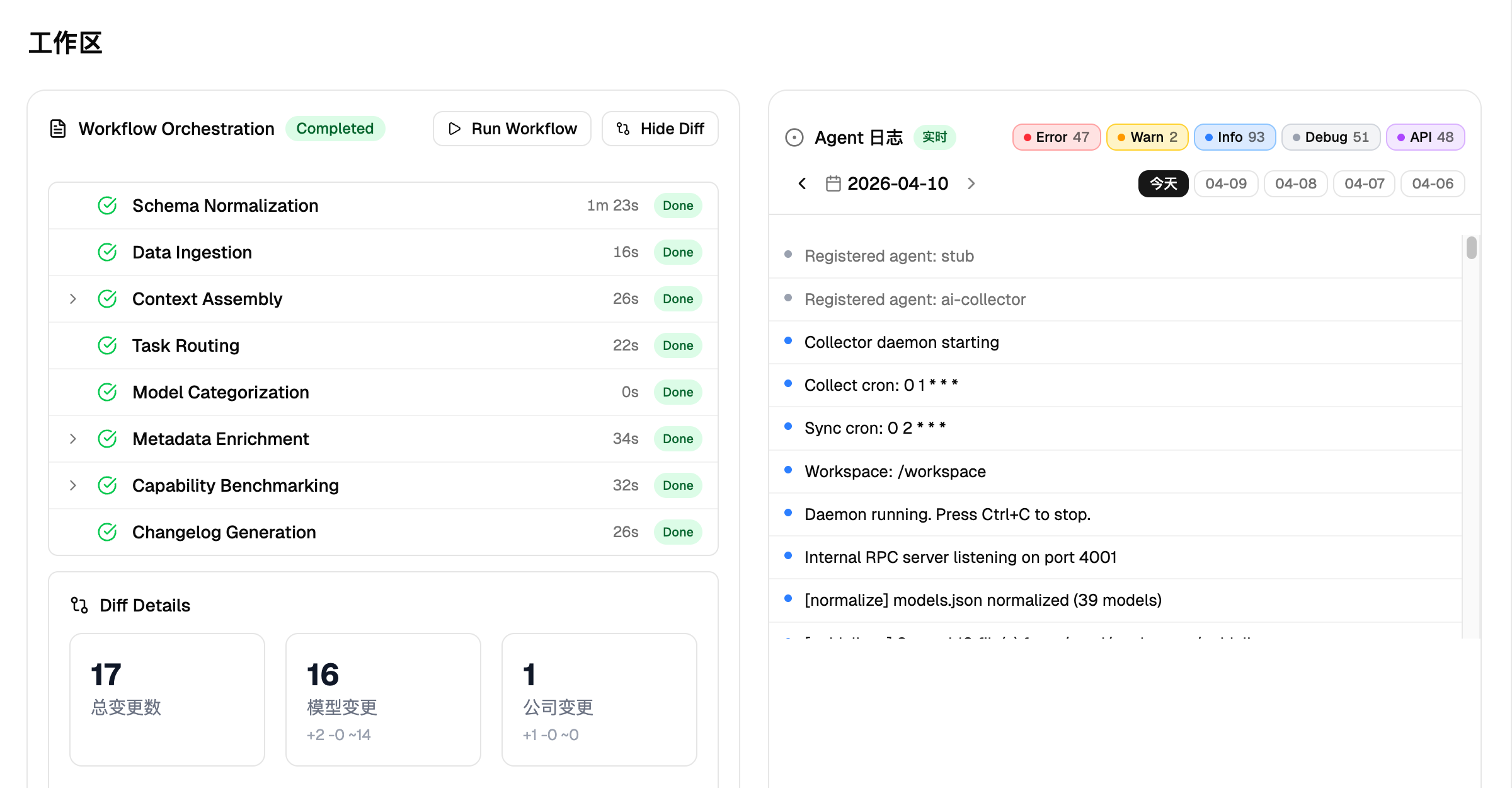
智能摄取代理是驱动网站自我进化的核心引擎,其技术实现涵盖独立进程调度、多阶段工作流编排及多源并行抓取三个关键层面。该组件以独立守护进程模式运行,支持四种运行方式:一是工作流模式(默认,执行八阶段编排后进入待审核);二是传统模式(单代理采集);三是守护进程模式(按计划任务默认每日凌晨一点自动触发);四是手动同步模式(绕过工作流直接写库)。代理的人工智能配置——包括供应商地址、模型标识与密钥——存储于工作空间配置文件而非环境变量,确保运行时灵活切换。代理内置八阶段自动化工作流,由编排引擎顺序调度各阶段并通过状态文件管理全局生命周期。八个阶段依次如下:
1. 模式规范化(Schema Normalization)
工作流启动的首个环节。系统加载工作空间中全部模型记录,提取每个模型的标识符、显示名称、所属公司、产品线、基础模型引用及别名列表,将其作为上下文提交给大语言模型进行审查。模型在最多二十轮工具调用循环中,借助外部搜索服务(Tavily)验证模型间关系,识别重复项、变体及别名。审查完成后,模型输出一组规范化动作指令,动作类型涵盖重命名(修正标识符或显示名称)、合并(移除重复条目)、标记变体(建立基础模型引用)、标记别名(追加别名记录)及设置产品线(分配产品线标识)。系统逐条执行这些动作,将变更写回工作空间模型文件,并将已应用的动作列表传递至后续阶段的上下文中。
2. 数据摄取(Data Ingestion)
并行子代理从多个权威数据源抓取最新模型信息。系统读取阶段专属指令文件中列出的目标网址,将其交由大语言模型驱动的抓取代理处理。代理在最多十五轮工具调用循环中,通过网页抓取工具逐一访问各数据源页面,提取页面内容后解析出结构化的模型数据——包括标识符、名称、所属公司、发布日期、上下文窗口大小、输入输出定价、开源状态、描述文本、产品线、版本号及基准测试分数。抓取完成后,代理调用终结工具输出全部已采集模型的结构化数组,该数据集被存入管道上下文供下游阶段消费。
3. 上下文装配(Context Assembly)
摄取的异构数据在此阶段合并至本地工作空间。系统读取当前工作空间的模型文件,将其与上一阶段采集的模型数据一并提交给大语言模型。模型通过三个工作空间操作工具——读取(按标识符查询已有记录)、创建(写入新模型条目并自动执行字段规范化)、更新(以补丁方式修改已有记录的指定字段)——在内存中操作模型列表。当采集数据量较小(不超过五条)时,由单一代理完成全部合并;数据量较大时,系统自动将采集结果按每批五条拆分,通过子代理池并行处理各批次,最终汇总所有批次的新增、更新与未变更记录。合并完成后,系统对全部模型执行字段规范化清洗,将结果写回工作空间文件。
4. 任务路由(Task Routing)
系统为新摄入的模型数据分配所属公司与产品线标识。此阶段仅在上下文装配阶段产生了新增模型时触发,否则自动跳过。代理读取工作空间中的公司定义文件、产品线定义文件与模型文件,审查每个新增模型的归属关系。若模型所属公司或产品线尚未在工作空间中注册,代理通过创建工具新建公司条目(含标识符、名称、国别及中国可用性状态)或产品线条目(含标识符、显示名称及所属公司引用)。随后,代理通过更新工具为每个新增模型设置 companySlug 与 seriesSlug 字段。全部分类完成后,系统将模型、公司与产品线三个文件同步写回工作空间。
5. 模型分类(Model Categorization)
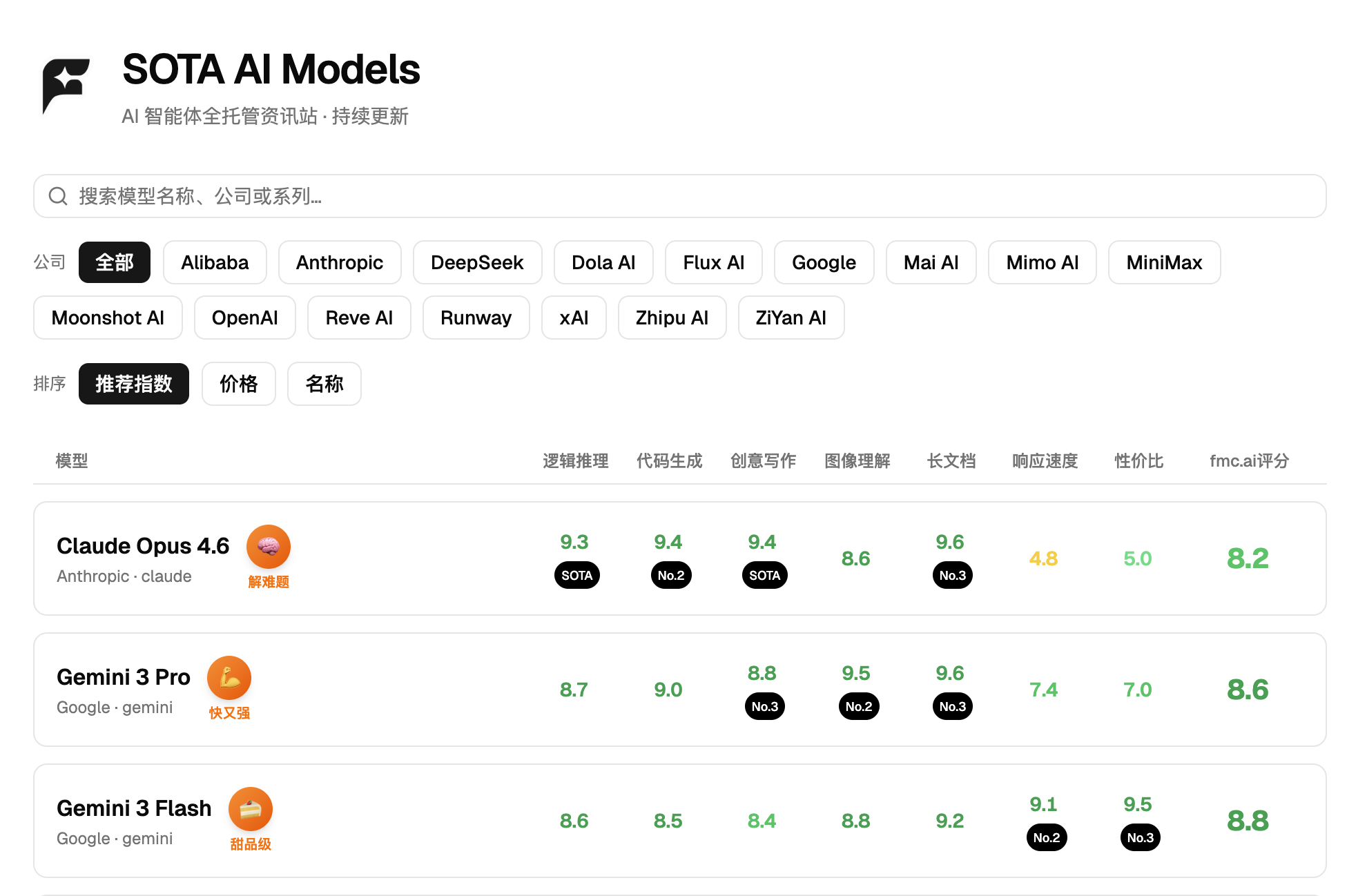
模型按类别字段被划分为通用对话、视频生成、音频生成、图像生成或其他特定领域。此阶段采用基于规则的确定性分类而非大语言模型推理:系统遍历全部模型,将模型名称与描述文本拼接后进行正则匹配——命中视频相关关键词(video、sora、runway、pika、gen-3)归入视频生成类别;命中音频相关关键词(audio、tts、speech、voice、whisper)归入音频生成类别;命中图像生成关键词(dall-e、midjourney、stable diffusion、imagen、flux)且未命中多模态理解关键词时归入图像生成类别;其余模型保持默认的通用对话类别。分类变更被写回工作空间,同时输出各类别的数量分布统计。前端展示层仅过滤并呈现通用对话类别的模型数据。
6. 元数据增强(Metadata Enrichment)
系统触发网络搜索填补缺失字段并纠正潜在错误。此阶段筛选需要增强的模型——包括上下文装配阶段新增或更新的模型,以及任何关键字段(发布日期、上下文窗口、输入定价、输出定价、描述、开源状态)存在缺失的模型。代理通过网络搜索工具(Tavily)与网页抓取工具查找每个模型的权威信息,随后通过更新工具补全缺失字段或修正错误数据,同时支持修正公司信息。当待增强模型数量不超过三个时由单一代理处理(最多三十轮工具调用),超过三个时按每批五个拆分为子代理池并行处理(最大并发数为三,以控制搜索服务速率限制)。全部增强完成后,系统对模型与公司文件执行规范化并写回工作空间。
7. 量化基准评测(Capability Benchmarking)
系统在推理、编程、写作、多模态、上下文窗口、运行速度与使用成本七个核心维度上,以十分制(精度 0.1)对模型能力进行量化评分。此阶段筛选任何评分维度存在缺失的模型,通过网络搜索工具查找各模型的基准测试数据与性能评测报告,由推理模型(而非普通采集模型)进行分析判断后,调用专用评分更新工具写入各维度分数。系统对每个分数值执行范围校验(0–10)与精度四舍五入。待评分模型按每批十个拆分,通过子代理池以最大三并发并行处理。评分完成后,全部模型数据经规范化写回工作空间。
8. 变更日志生成(Changelog Generation)
工作流的最终环节,产出具备高可观测性的差异分析报告。系统汇总前七个阶段的全部执行数据——包括采集模型数量、新增与更新与未变更记录数、分类结果、新建公司与产品线数、增强与修正记录数、评分模型数——将其作为结构化摘要提交给大语言模型。模型依据阶段专属指令中定义的报告格式,生成一份完整的 Markdown 变更报告。报告生成后被写入管道状态文件,供管理控制台的人工审核环节直接展示。工作流至此进入待审核状态,等待管理员在审核闸门中做出批准或驳回的最终决策。
二、双层数据架构与人工审核闸门
数据流转采用工作空间与关系型数据库双层结构,其核心节点包括种子数据初始化、工作流状态管理、人工审核闸门及自动化同步写库。摄取代理在隔离的本地运行环境中操作结构化文件,该运行时工作空间通过容器卷挂载实现分层持久化。系统预置纳入版本控制的种子工作空间,包含公司定义(含名称、国别与中国可用性)、产品线规划、初始模型记录以及工作空间元数据。代理在工作流执行期间生成状态快照与历史备份,状态文件记录从运行中到待审核再到完成或驳回的完整生命周期,确保任意阶段的可恢复性。工作流执行完毕进入待审核状态。管理控制台引入人工介入机制,管理员审查变更报告可选择批准或驳回,此环节构成系统的安全决策边界。批准操作触发同步服务执行多步写库流程:一是系统依次加载公司映射,将产品线与模型数据以增补更新方式写入关系型数据库各对应表;二是期间自动完成工作空间字段命名到数据库字段命名的规范化转换;三是系统为每个模型创建每日评分快照记录,并生成包含新增数量、更新数量与快照数量的详细同步日志。驳回操作指令系统回滚至运行前备份状态。该机制保障数据自动获取效率,维持极高信息准确度。系统构建严密数据模型支撑复杂资讯展示需求,其关键设计涵盖实体标识、任务路由、产品线归属与能力评估四个维度。每个模型实体包含唯一标识符、显示名称与所属企业标识。分类系统默认将模型归入通用对话类别,特定模型被精确路由至多媒体生成细分领域,前端展示层仅过滤并呈现通用对话类别的模型数据。产品线字段取代已废弃的传统家族分类体系,清晰界定模型所属商业序列。系统支持定义基础模型与变体模型间的继承关系,其判定规则严格明确:一是推理版本被严格定义为变体;二是参数规模差异不构成变体关系。模型能力基准评测体系涵盖推理、编程、写作、多模态、上下文窗口、运行速度与使用成本七个量化指标,均采用十分制。
三、解耦分层的单一代码仓库与容器化部署
本项目采用基于单一代码仓库架构模式管理多端应用。系统整体划分为前端展示层、后端数据服务层、智能摄取代理、管理控制台四个核心模块,另设共享类型包。各模块通过共享类型定义实现严格的数据规约。系统设计的核心在于将人工智能逻辑与基础数据服务完全剥离:一是后端服务基于成熟的服务端框架与对象关系映射工具构建,仅作为纯粹的数据提供层运作,对外暴露接口供前端读取摄取代理所汇聚的数据,自身不承载任何人工智能推理逻辑;二是前端应用采用现代构建工具与组件框架的单页架构,刻意摒弃传统路由库,页面导航完全由组件状态驱动。这种解耦设计确保面向用户界面的高响应速度与后端接口的极简性。生产环境部署依托容器化技术实现服务隔离协同,编排文件定义数据库、后端接口、前端页面、摄取代理与管理面板五个服务。系统采用边缘路由策略处理外部流量,其分发逻辑涵盖多个层面:一是边缘节点将接口请求精准分发至后端数据服务容器;二是其余访问流量被导向前端静态资源服务,由轻量级反向代理提供单页应用回退;三是前端服务与管理面板内部均配置反向代理机制,保留接口前缀而非剥离,确保跨域请求无缝转发且同源访问无需额外跨域配置。后端服务配置全局统一接口前缀,并监听所有网络接口保障容器间通信顺畅。系统内置完善健康检查与错误恢复机制,网络层面异常通过重启相关容器重置内部域名解析缓存迅速恢复。指导摄取代理行为的系统指令——涵盖总则及各阶段专属指令的文档集——被视为核心代码资产。
项目展示
https://sota.fmc.ai/